RPC接口超时怎么解决?
项目场景:
在日常的系统维护中,『服务超时』应该属于监控报警最多的一类问题。
尤其在微服务架构下,一次请求可能要经过一条很长的链路,跨多个服务调用后才能返回结果。当服务超时发生时,研发同学往往要抽丝剥茧般去分析自身系统的性能以及依赖服务的性能,这也是为什么服务超时相对于服务出错和服务调用量异常更难调查的原因。
问题描述
本文章将根据自己在实际开发的优化经验,给出一些优化方法,以及该如何正确理解并设置RPC接口的超时时间
原因分析:
很多同学在遇到rpc超时的时候,是不是会去调整超时时间,看似容易,其实暗藏玄机
RPC框架的超时重试机制到底是为了解决什么问题呢?从微服务架构这个宏观角度来说,它是为了确保服务链路的稳定性,提供了一种框架级的容错能力。微观上如何理解呢?可以从下面几个具体case来看:
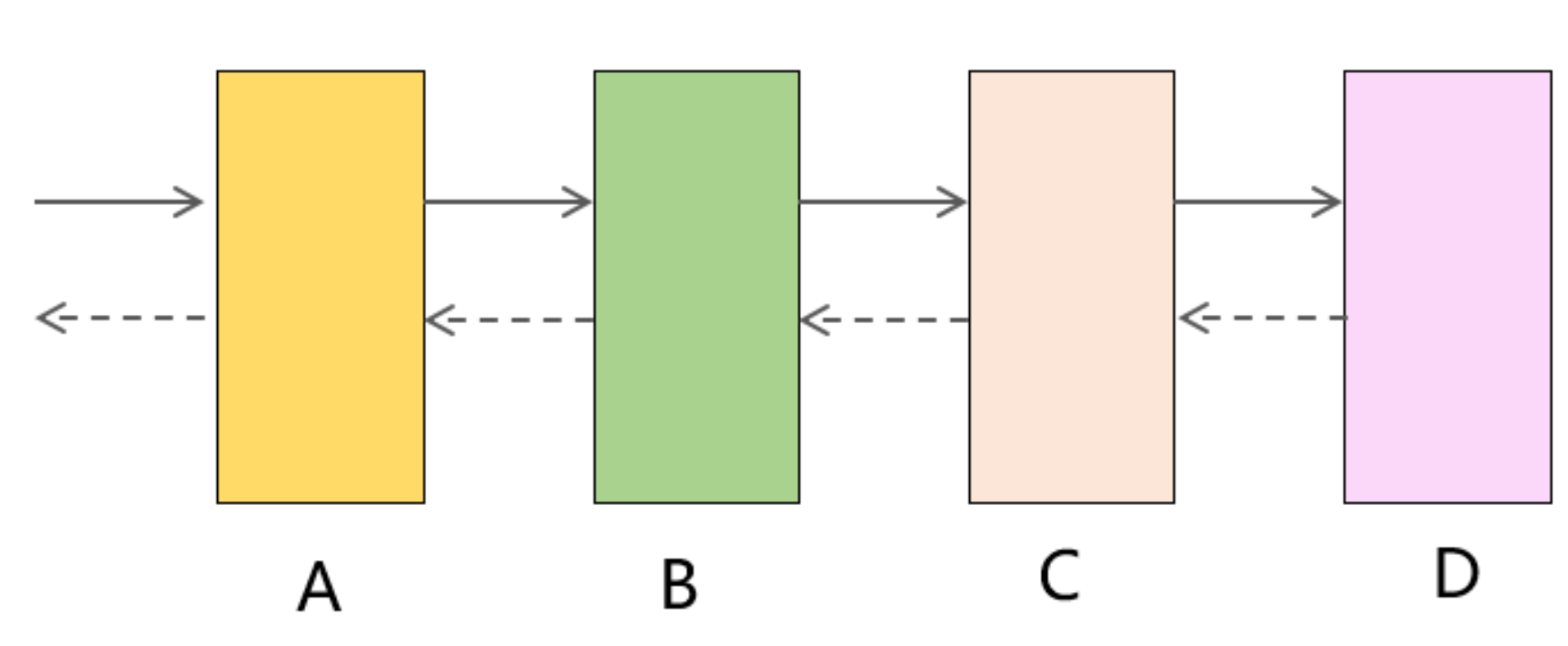
1、consumer调用provider,如果不设置超时时间,则consumer的响应时间肯定会大于provider的响应时间。当provider性能变差时,consumer的性能也会受到影响,因为它必须无限期地等待provider的返回。假如整个调用链路经过了A、B、C、D多个服务,只要D的性能变差,就会自下而上影响到A、B、C,最终造成整个链路超时甚至瘫痪,因此设置超时时间是非常有必要的。
2、假设consumer是核心的商品服务,provider是非核心的评论服务,当评价服务出现性能问题时,商品服务可以接受不返回评价信息,从而保证能继续对外提供服务。这样情况下,就必须设置一个超时时间,当评价服务超过这个阈值时,商品服务不用继续等待。
3、provider很有可能是因为某个瞬间的网络抖动或者机器高负载引起的超时,如果超时后直接放弃,某些场景会造成业务损失(比如库存接口超时会导致下单失败)。因此,对于这种临时性的服务抖动,如果在超时后重试一下是可以挽救的,所以有必要通过重试机制来解决。
但是引入超时重试机制后,并非一切就完美了。它同样会带来副作用,这些是开发RPC接口必须要考虑,同时也是最容易忽视的问题:
1、重复请求:有可能provider执行完了,但是因为网络抖动consumer认为超时了,这种情况下重试机制就会导致重复请求,从而带来脏数据问题,因此服务端必须考虑接口的幂等性。
2、降低consumer的负载能力:如果provider并不是临时性的抖动,而是确实存在性能问题,这样重试多次也是没法成功的,反而会使得consumer的平均响应时间变长。比如正常情况下provider的平均响应时间是1s,consumer将超时时间设置成1.5s,重试次数设置为2次,这样单次请求将耗时3s,consumer的整体负载就会被拉下来,如果consumer是一个高QPS的服务,还有可能引起连锁反应造成雪崩。
3、爆炸式的重试风暴:假如一条调用链路经过了4个服务,最底层的服务D出现超时,这样上游服务都将发起重试,假设重试次数都设置的3次,那么B将面临正常情况下3倍的负载量,C是9倍,D是27倍,整个服务集群可能因此雪崩。
编辑
应该如何合理的设置超时时间?
理解了RPC框架的超时实现原理和可能引入的副作用后,可以按照下面的方法进行超时设置:
设置调用方的超时时间之前,先了解清楚依赖服务的TP99响应时间是多少(如果依赖服务性能波动大,也可以看TP95),调用方的超时时间可以在此基础上加50%
如果RPC框架支持多粒度的超时设置,则:全局超时时间应该要略大于接口级别最长的耗时时间,每个接口的超时时间应该要略大于方法级别最长的耗时时间,每个方法的超时时间应该要略大于实际的方法执行时间
区分是可重试服务还是不可重试服务,如果接口没实现幂等则不允许设置重试次数。注意:读接口是天然幂等的,写接口则可以使用业务单据ID或者在调用方生成唯一ID传递给服务端,通过此ID进行防重避免引入脏数据
如果RPC框架支持服务端的超时设置,同样基于前面3条规则依次进行设置,这样能避免客户端不设置的情况下配置是合理的,减少隐患
如果从业务角度来看,服务可用性要求不用那么高(比如偏内部的应用系统),则可以不用设置超时重试次数,直接人工重试即可,这样能减少接口实现的复杂度,反而更利于后期维护
重试次数设置越大,服务可用性越高,业务损失也能进一步降低,但是性能隐患也会更大,这个需要综合考虑设置成几次(一般是2次,最多3次)
如果调用方是高QPS服务,则必须考虑服务方超时情况下的降级和熔断策略。(比如超过10%的请求出错,则停止重试机制直接熔断,改成调用其他服务、异步MQ机制、或者使用调用方的缓存数据)
解决方案:
这里给出一些常见的解决方案,以及个人实战经验
1. 数据库 SQL 优化
通过 explain 计划分析 SQL 执行路径
Kill 慢 SQL
常见问题与优化点
未加索引、索引失效(字段类型不一致、函数使用、区分度低等)
查询数据过大(分页 + 批次、limit 优化)
拆分大 SQL(如多表 JOIN 查询,建议先查主表,再用外键查子表拼接)
尽量避免在 SQL 中做复杂计算逻辑
建议
数据量大的表:可考虑异步化、批处理
可使用分表、分库策略,或采用异构存储如
ClickHouse、ES
2. 调用第三方服务慢
请求慢的原因可能是网络耗时、并发量大、对方接口慢等
手段
使用
Sentinel或Hystrix做限流、熔断,防止下游异常拖垮本服务设置超时时间(考虑 P95、P99 接口响应时间)
批量化调用(避免单次频繁调用,如 for 调用可合并一次调用)
预热机制(提前请求并缓存结果)
异步调用改造(Job 异步执行,提高响应速度)
3. 中间件问题
Redis
查询慢可能是 key 太大、集合太大、频繁拆分 key、判断操作如
sismember
Kafka
生产慢:压缩配置、分区配置
消费慢:消费者线程少、批量写入慢、未开启批量消费
4. 程序代码问题
并发处理差
没有使用线程池、异步线程、并发框架,如
CompletableFuture
不合理的同步锁
例如:大量线程阻塞在锁上,或者 synchronized 粒度大
数据处理不高效
可考虑本地缓存、异步线程处理、合并调用
以下是个人在实战的时候遇到的问题:
在一次调用的rpc接口时,出现了超时问题,由于原本的代码涉及的业务和逻辑都不是我来做的,优化的这个任务落到了我的头上,一时满头大汗,如何在不修改逻辑的情况下优化时间呢?
空间换时间!
来看看原来的代码是怎么写的
List<RoleGroupModel> roleGroupModelList = queryUserEffectiveRoleGroupList(uid, false);
RoleGroupModel roleGroupModel = roleGroupModelList.stream().filter(item -> item.getId() == roleGroupId).findAny().orElse(null);
if (roleGroupModel == null) {
log.warn("roleGroupModel not found, uid:{}, roleGroupId:{}", uid, roleGroupId);
return null;
}
roleGroupModel.setEmotionBondModel(queryEmotionBondModel(uid, roleGroupId, false));
roleGroupModel.setEmotionBondPopupStatus(queryUserEmotionBondStartStatus(uid, roleGroupId));
可以看到涉及到了三个查询到,其中这三个查询方法涉及到多张表的查询,有的方法是全表扫描,有的表是根据主键查询,优化起来很麻烦,于是使用CompletableFuture进行编排
AsyncWork.supplyAsync(() -> {
List<RoleGroupModel> roleGroupModelList = queryUserEffectiveRoleGroupList(uid, false);
return roleGroupModelList.stream().filter(item -> item.getId() == roleGroupId).findAny().orElse(null);
},ThreadPoolFactory.acquire(ThreadPoolConfig.REDIS_EXECUTOR_POOL.getPoolName()), roleBondBo::setRoleGroupModel);
AsyncWork.supplyAsync(
() -> RoleComponent.this.queryEmotionBondModel(uid, roleGroupId, false),
ThreadPoolFactory.acquire(ThreadPoolConfig.REDIS_EXECUTOR_POOL.getPoolName()), roleBondBo::setEmotionBondModel);
AsyncWork.supplyAsync(
() -> RoleComponent.this.queryUserEmotionBondStartStatus(uid, roleGroupId),
ThreadPoolFactory.acquire(ThreadPoolConfig.REDIS_EXECUTOR_POOL.getPoolName()), roleBondBo::setEmotionBondSwitch
);
Work.complete();