有 MySQL 为什么还要有 MongoDB?游戏业务的主力数据库
概要
现在要做一个游戏平台,这个平台得支撑十多亿游戏用户数据的写入和存储。游戏用户的数据包含多种字段,比如id、装备、是否参与过节日活动等,而且功能还在不断迭代,需要支持扩展各种属性字段,同时还要满足多维度查询的需求。比如说,要查询没参加过情人节活动的角色有哪些,这时候问题就来了,你会选择用什么来存储这么大量的游戏数据呢?
MySQL
聊到数据存储,很多人很容易就会想到使用 MySQL 数据库,把用户的 id、装备、参与的活动等信息做成一个像 Excel 那样的数据表。为了支持多维度查询,还需要为每个可能的属性都预留字段,甚至要给这些字段加上索引,比如预留春节、情人节活动等各种字段。但实际情况是,大多数角色并不会参与全部的活动,所以很多预留的字段根本就用不上,这就造成了空间的浪费。而且游戏迭代非常频繁,每次增加新活动的时候,都需要修改表结构,操作起来特别麻烦。

MongoDB
那问题就来了,有没有一种既灵活又高效的存储方案呢?在IT领域,不是常说“没有什么是加一层中间层不能解决的,如果有,那就再加一层”嘛。这次


BSON编码
二进制JSON,是MongoDB的底层数据格式,在JSON基础上扩展了对二进制等更多数据类型的支持,写入磁盘的是用xx.wt 格式的
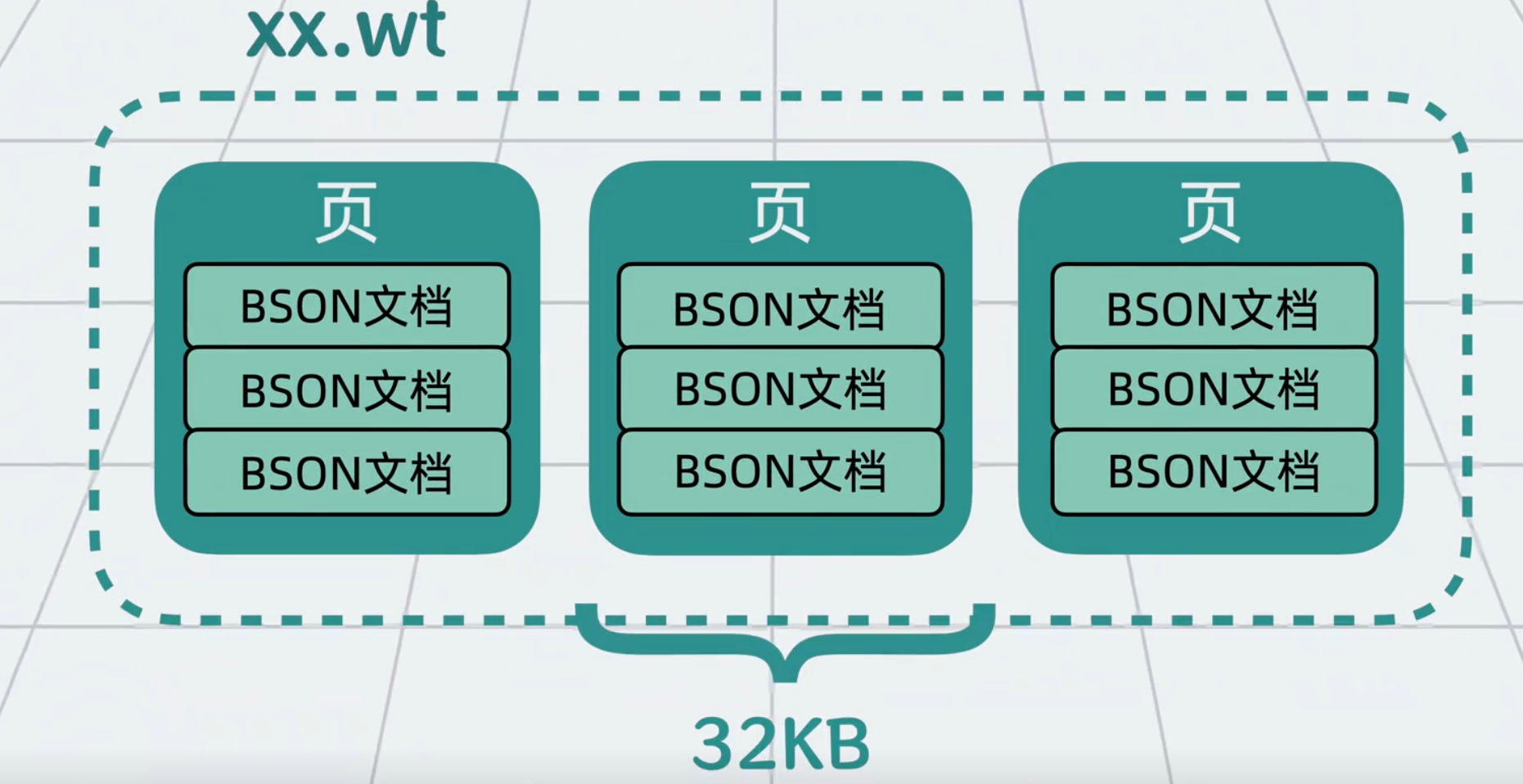
把一个个 BSON 文档组成的集合写到磁盘里,形成以xx.wt 为后缀名的文件。集合越大,磁盘上的xx.wt 文件也就越大。如果直接读写一个大文件里的全部数据,速度会非常慢,所以 MongoDB 会把数据拆成一个个数据页,每个数据页的大小是 32KB。现在,如果需要通过服务进程读写某些 BSON 文档数据,就只需要读写磁盘里的某几个数据页就好,不需要加载整个xx.wt 文件,这样就大大减少了 IO 开销。
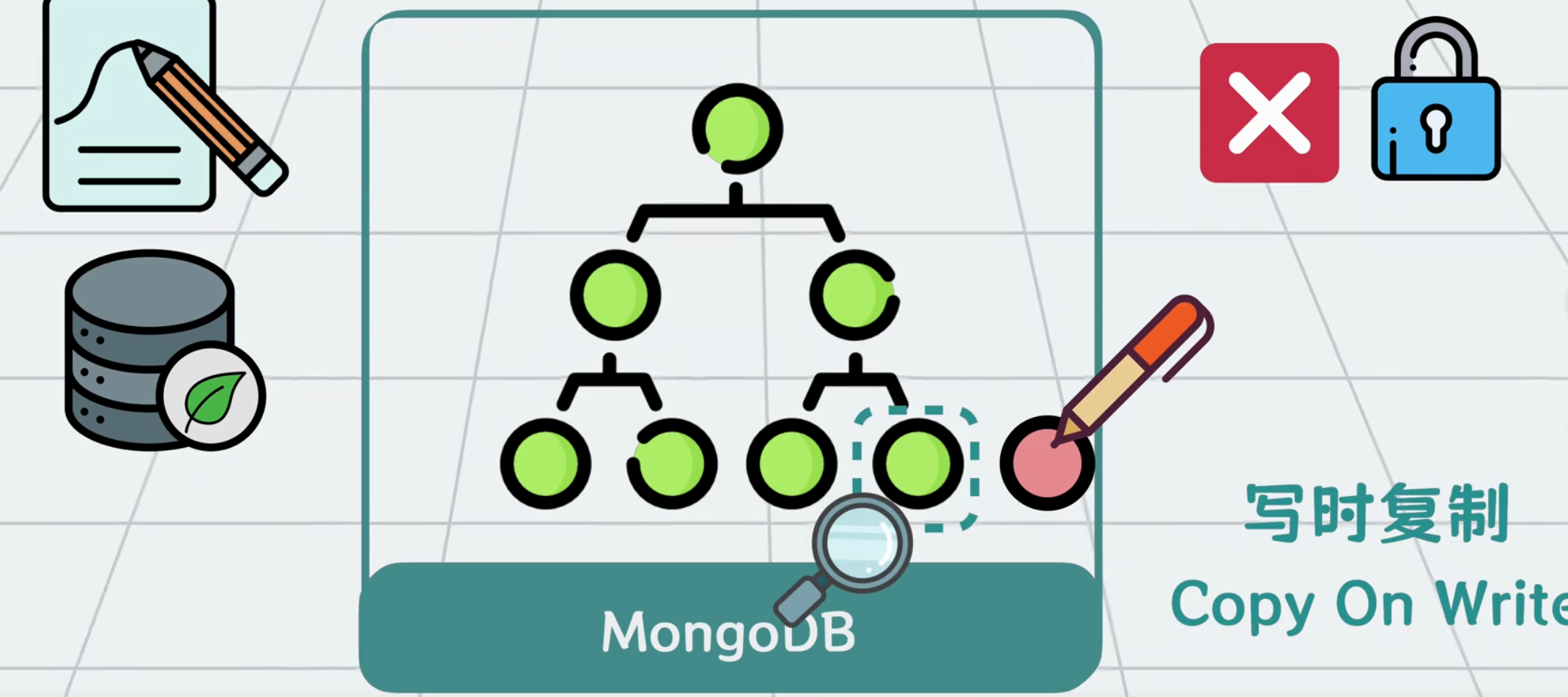
变种B+数索引
相同点:与MySQL一样,使用 B+树 来加速查询。主键ID有主键索引,其他字段可以创建辅助索引。
不同点:MySQL 在更新 B + 树的数据页时,为了防止并发写冲突,会在从根节点到叶子节点的搜索过程中加入短暂的内存锁,并且对目标页的行记录加锁;而 MongoDB 在写数据时,几乎不对数据页加锁,而是直接复制一个新的数据页出来进行写入,这就是所谓的 “写时复制(Copy on Write)”。
这样一来,原来的数据页还能对外提供读操作,写操作则在新的数据页上进行,两者互不影响,之后再找机会把复制出来的新数据页合并到原有的 B + 树结构中,这样并发读写性能会更好。从效果上看,就像是在原来的 B + 树基础上挂了多个复制页,所以本质上这是一种变种 B + 树。
内存
将热点数据页存入内存,查询优先读缓存,未命中再读磁盘;用 LRU(最近最少使用)策略清理内存,保证缓存数据为热点数据。
数据持久化保障(WiredTiger)
写前日志(WAL):所有写操作先记录到
journal buffer,再刷新到磁盘journal文件,服务崩溃后可通过日志重做数据,避免丢失;顺序写journal文件的性能是随机写磁盘的几十倍。Checkpoint 机制:定期将内存中修改过的 “脏页” 批量写入磁盘,写完后删除此前的
journal日志,平衡磁盘 IO 与性能。
小结
MongoDB的灵活文档模型在处理游戏中的复杂数据结构时表现尤为出色。游戏存在不同场景下大量的全量更新和增量更新行为,游戏中包括玩家信息、游戏状态、物品信息等在内的数据结构会频繁发生变化,与此同时,优化占比大的字段还可能带来工作负载的更新。MongoDB采用文档存储的方式,使用JSON格式来存储数据。每个文档可以有不同的字段和结构,这使得它非常适合处理游戏中的复杂数据。通过使用MongoDB,开发人员可以随时添加或修改字段而不需要进行复杂的数据库迁移操作。