MySQL 间隙锁导致的死锁!全链路实战排查!
项目场景:
在开发项目中,其中包含银币消费的高并发业务场景。该场景,数据库为 MySQL InnoDB,引入了 Druid 连接池作为连接管理中间层,默认使用 REPEATABLE-READ 隔离级别。在用户大量并发消费银币时,频繁触发数据库操作及事务控制。
问题描述
线上频繁抛出如下异常:
java.sql.SQLException: connection holder is null
同时观察到 Druid 连接池连接数快速增长并耗尽,导致大量业务请求失败。进一步分析还发现,在部分并发请求中伴随着数据库死锁问题。
原因分析:
1.初步排查连接池问题:Druid 连接被遗弃但未清除引用
1.排查druid配置
DruidPooledConnection是一个静态代理,持有ConnectionHolder, connection Holder里持有具体的connection对象, 可以看到在数据源连接在执行druidPooledConnection的所有和数据库相关方法时,都会先调用checkState()判断connection holder是否为null,如果是null就抛connection holder is null的异常。
druid连接池参数
销毁空闲连接 shrink方法
当一个连接长时间没有被使用,如果不及时清理就会造成资源浪费,所以需要定时检查空闲时间过长的连接进行断开连接销毁
2.回收超时连接 removeAbandoned方法
当一个连接被一个线程长时间占有没有被归还,有可能是程序出故障了或是有漏洞导致迟迟没有归还连接,这样就可能会导致连接池中的连接不够用,所以需要定时检查霸占连接时间过长的线程,如果超过规定时间没有归还连接,则强制回收该连接。
该项目中的druid配置
testOnBorrow=false
testOnReturn=false
maxOpenPreparedStatements=100
removeAbandoned=true
removeAbandonedTimeout=60
如果连接池配置中 testOnBorrow(借用连接时验证有效性)被设置为 false,应用程序在获取连接时不会检查其是否有效,可能直接拿到一个已失效的连接。
如果 testWhileIdle(空闲时验证)启用,但检测周期(timeBetweenEvictionRunsMillis)设置过长,失效连接可能未被及时清理。
但是开启testOnBorrow会导致性能消耗,生产环境下不建议开启
初步来看druid配置没有问题
2. 是否是开启了事务的原因
事务实现方式
在Spring中,事务有两种实现方式:
编程式事务管理: 编程式事务管理使用TransactionTemplate可实现更细粒度的事务控制。
申明式事务管理: 基于Spring AOP实现。其本质是对方法前后进行拦截,然后在目标方法开始之前创建或者加入一个事务,在执行完目标方法之后根据执行情况提交或者回滚事务。申明式事务管理不需要入侵代码,通过@Transactional就可以进行事务操作,方便快捷,且不会出错。
项目中使用的是声明式事务,使用事务的方法也都正确引用,不存在事务并没有提交或者回滚。
3. 排查数据库的原因
定位到目标代码
@Transactional(rollbackFor = Exception.class)
public UserSilverCoinAccount getOrCreateUserSilverCoinAccount(int userId) {
UserSilverCoinAccount userSilverCoinAccount = userSilverCoinAccountMapper.getUserAccountForUpdate(userId);
if (userSilverCoinAccount == null) {
userSilverCoinAccount = new UserSilverCoinAccount().setUserId(userId).setBalance(NumberUtils.INTEGER_ZERO); // 余额初始值为0
log.info("create UserSilverCoinAccount userId:{}", userId);
userSilverCoinAccountMapper.insertSelective(userSilverCoinAccount);
}
return userSilverCoinAccount;
}
查看错误日志,发现报错都是成对出现的,而且是同一时间,判断是并发情况下导致的事务问题
分析这个代码的逻辑:
事务管理:使用 @Transactional(rollbackFor = Exception.class) 确保方法在发生异常时回滚,保持数据一致性。
查询现有账户:通过 userSilverCoinAccountMapper.getUserAccountForUpdate(userId) 查询用户 userId 对应的账户,并使用 forUpdate 锁机制防止并发问题。
创建新账户:如果账户不存在(null),则:
创建一个新的 UserSilverCoinAccount 对象。
设置 userId 和初始余额为 INTEGER_ZERO(0)。
记录日志,提示创建新账户。
通过 userSilverCoinAccountMapper.insertSelective 插入新记录。
查询语句:
SELECT * FROM user_silver_coin_account WHERE user_id = ? FOR UPDATE
其中user_id 是唯一索引,在数据库中会为匹配的 user_id 行添加一个记录锁。
这种锁在事务中生效,具有以下特点:
排他锁:其他事务无法同时对被锁定的行执行更新或删除操作(SELECT ... FOR UPDATE 也会阻止其他事务的更新)。
并发控制:确保在当前事务完成前,同一行数据不会被其他事务修改,防止并发问题(如重复创建账户)。
释放时机:锁会在当前事务提交(COMMIT)或回滚(ROLLBACK)时释放。
在查询user_id 存在的时候是没有问题的,并发情况下只能拿到一个锁,不会出现死锁的情况
但是在user_id不存的时候,记录锁会退化成间隙锁
如果 SELECT ... FOR UPDATE 查询条件没有命中任何记录,但使用了唯一索引,InnoDB 为了防止幻读,会对这个“应该在的位置”加上间隙锁(Gap Lock)。
4. 开始测试
实践是检验真理的唯一标准
事务A 查询不存在的记录

事务B 插入数据


结果

编辑
锁类型:RECORD X + GAP (Record Lock + Gap Lock):
很明显,记录锁会退化成间隙锁了
5. 间隙锁有哪些坑?
间隙锁触发条件
在可重复读(Repeatable Read)事务隔离级别下,以下情况会产生间隙锁:
使用普通索引锁定:当一个事务使用普通索引进行条件查询时,MySQL会在满足条件的索引范围之间的间隙上生成间隙锁。
使用多列唯一索引:如果一个表存在多列组成的唯一索引,并且事务对这些列进行条件查询时,MySQL会在满足条件的索引范围之间的间隙上生成间隙锁。
使用唯一索引锁定多行记录:当一个事务使用唯一索引来锁定多行记录时,MySQL会在这些记录之间的间隙上生成间隙锁,以确保其他事务无法在这个范围内插入新的数据。
间隙锁有以下加锁规则
规则1:加锁的基本单位是 Next-Key Lock,左开右闭区间。
规则2:查找过程中访问到的对象才会加锁。
规则3:唯一索引上的范围查询会上锁到不满足条件的第一个值为止。
规则4:唯一索引等值查询,并且记录存在,Next-Key Lock 退化为行锁。
规则5:索引上的等值查询,会将距离最近的左边界和右边界作为锁定范围,如果索引不是唯一索引还会继续向右匹配,直到遇见第一个不满足条件的值,如果最后一个值不等于查询条件,Next-Key Lock 退化为间隙锁。
间隙锁产生死锁的原因
编辑
间隙锁锁定的范围
间隙范围为:(-∞, 100)、(100, 200)、(200, 300)、(300, +∞)。SELECT * FROM user_silver_coin_account WHERE user_id = 250 FOR UPDATE;
间隙锁锁定的是 (200, 300) 范围。
分析死锁产生过程
在同一个事务里,流程是这样的:
SELECT … FOR UPDATE查不到记录 ⇒ 加间隙锁START TRANSACTION; SELECT * FROM user WHERE id = 100 FOR UPDATE;由于
id=100在表里不存在,InnoDB 会对它“本应出现的位置”的间隙加一个间隙锁(gap lock),防止其他事务在该位置插入。随后执行
INSERTINSERT INTO user (id, name) VALUES (100, 'alice');在这个同一事务内,插入操作会走以下加锁步骤:
插入意向锁(insert intention lock):InnoDB 在该间隙上打一个意向锁,表明“我要在这里插入新行”,但这种锁 不会 与其它插入意向锁冲突。
记录锁(record lock,X 锁):新行一旦写入,马上对这条新记录本身加一个排它(X)行锁,直到事务提交或回滚才释放。
间隙锁升级为记录锁:当一个事务持有间隙锁,并且另一个事务尝试插入一条记录到这个间隙中时,如果插入的记录会使得原本的间隙锁被拆分,那么间隙锁会先释放,然后转换为两个间隙锁和一个记录锁,其中记录锁锁定的是新插入的记录。
于是,就出现了这样一个死锁循环:
事务 A
SELECT … FOR UPDATE WHERE user_id=200
⇒ 因为 200 不存在,给“200 这个点”所在的间隙打了一个 gap-lock。紧接着要
INSERT user_id=200申请一个 insert-intention 锁(这个不冲突,大家都能拿)
尝试把 gap-lock 升级为新行的 Record Lock
⇒ 这个升级需要排它地占有整个 gap 区间。
事务 B
同样地,先后拿到对“200”同一个间隙的 gap-lock。
它也会在 INSERT 时尝试把自己的 gap-lock 升级成对新记录的 Record Lock。
但两个事务此时都各自持有 gap-lock,都在同时「等待对方先释放 gap-lock,好把它升级成 Record Lock」。
A 等 B:等 B 先放掉 gap-lock,好让自己升级
B 等 A:等 A 先放掉 gap-lock,好让自己升级
这就是一个循环等待,典型的死锁――并不是因为它们在记录层面互相等锁,而是在 gap-lock → record-lock 的转换上互相等对方先放手。
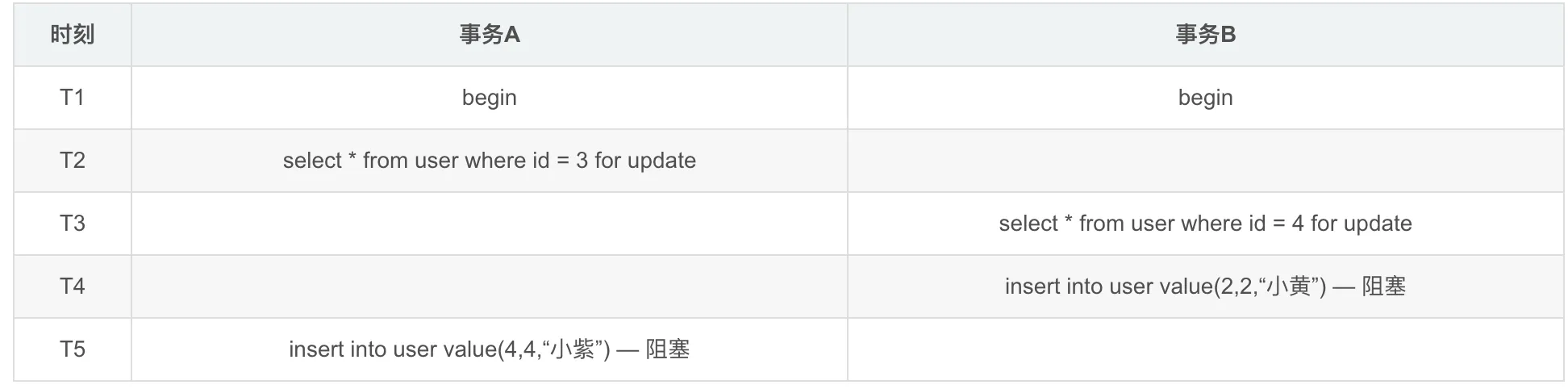
实验
事务A

事务B:

编辑
事务A和事务B同时查询,同时获得间隙锁
事务A 插入数据,开始阻塞,事务B插入数据,发生死锁
结果:出现了死锁

6.总结
gap-lock 本身是非排它的,所以两笔事务都能先拿到它。
但插入新行时要把它「升级」成真正锁行(record-lock),升级操作却是排它的。
两者都持有 gap-lock,又都在等待对方释放 gap-lock,于是死锁。
这正是一条由间隙锁引发的死锁,最终演化为连接池资源耗尽的多米诺骨牌式故障
解决方案:
数据库的锁机制,像是一位严谨但内向的看门人。他默不作声地守护着数据的边界,却常常因为太过细致而让人迷失于规则之中。**间隙锁、行锁、意向锁、死锁……**这些错综复杂的机制在高并发场景下,往往像一张无形的网,把系统推入无法预料的僵局。
在你以为“加把锁就能解决问题”的时候,其实已经走进了锁带来的复杂性漩涡。尤其是当一条数据尚不存在时,InnoDB 出于“保护未来”的善意加上间隙锁,却在无声中埋下死锁的种子。
与其在数据库锁的迷宫中举步维艰,不如将并发控制的主动权握在手中。分布式锁,就像是站在门外的引导者——用 Redis、ZooKeeper 等组件,为关键资源设定规则,用明确、可控的方式,在业务层提前阻挡冲突与混乱的发生。
与其让数据库背负“不该由它决定”的并发命运,不如让分布式锁在业务逻辑的入口处,守住那扇门。